在笔者学生时代,一直单纯地认为正则都是后端老哥的事儿,前端只要 split 一把梭就够了。万不得已的时候就网上搜几段正则代码,copy 一下也能用。

这是维基百科上正则表达式的词条,截图只截了一屏,事实上这张正则表达式的表格两个屏幕都装不下。。。我第一次查的时候立马就弃了,于是很长一段时间里都在原地踏步,只会用用 ^ $ . *
最初见到正则表达式是在表单验证里,多少会用些 validate 的库,基本的电话 / 邮箱之类的校验都有现成的,真正自己写正则去校验输入格式的机会并不多。后来渐渐发觉正则表达式的魔力,它可以是前端工程师的一把利器。
日常琐事
1、老项目迁移,所有的 T.dom.getElementById('abc') 代码都要改成新的写法 $('#abc')
2、组件库升级,所有的 <el-dialog v-model="a" 必须改成 <el-dialog :visible.sync="a"
都是真实工作中的脏活累活,故事 1 中的项目有近 100 个页面,由于 T 库弃用了,不仅 T.dom.getElementById 还有 getElementByClass 等等调用都要改成 jquery 的写法。如果完全靠人肉,那是多么的苦力。
故事 2 中的组件库其实就是我们的 Element,我们原先很多项目都是 Element 1.x,要升级到 2.x,这个对话框的 breaking change 影响还挺大的,在 2.x 中通过 v-model 是无法唤起对话框的。因此要确保每个 el-dialog 都检查一遍,而模板代码里 el-dialog 的 v-model 可能不在第一个,属性多的时候还会换行,都需要火眼金睛。
聪明的读者肯定知道,靠人肉是个没有办法的办法,而且看多了也会眼花,最好还要 double check。虽然写正则表达式去找,也不能保证 100% 都覆盖,毕竟老项目里各种迷之代码都有,但正则能帮我们找出大部分,并且 replace 的时候也能避免输入错误,这样可以把精力放在 double check 上。
正则起源
正则表达式源于形式语言与自动机理论,关于形式化的内容不是本文的重点,感兴趣的朋友可以去 wiki 上查。
正则引擎的基础就是状态机,在编译原理中你一定会听说 NFA (非确定有限状态自动机) 与 DFA (确定有限状态自动机),关于 NFA / DFA 通俗的解释可以参考这篇文章。
正则表达式最早在 Unix 中的 sed 和 grep 命令中开始普及。如果你用过 sed "s/aaa/bbb/" 的话,其实可以写正则表达式来做更复杂的文本处理。
而在编程语言中,Perl 是第一个实现正则表达式引擎的语言。目前大部分语言都使用基于 NFA 的正则引擎。
怎么学正则
笔者走了一些弯路,先在实战中写正则,不会写就查正则的语法表,渐渐地大部分语法也就都记住了,需要查表的也越来越少了。其实我觉得正确的学习方式应该先完整地看一本入门书籍,对整体有宏观把控后,再在实战中反复练习和查表,回头再重看书,这样的记忆应该最深。
如果你还在为正则表达式的语法而健忘的话,推荐一本《正则表达式必知必会》,这本书只有 100 页,一个周末就能看完。以后再查语法表的时候,就会越来越有规律可循。
正则表达式的语法可分为这几大类
- 匹配字符
- 匹配位置
- 重复与贪婪
- 分组与捕获
- 前后断言
本文并不介绍正则表达式语法,只通过实际工作的例子来说明正则的用途。可以先根据以上几个分类,在正则表达式的语法表里再过一遍。
1、URL里的暗号
在公司的开发环境中,一般都会有两套以上的测试环境,如 alpha 和 beta 环境。而在前端页面,我们通常使用不同的 URL 来区分,例如 jack.alpha.domain.com 与 jack.beta.domain.com 分别对应 alpha 和 beta 环境,而 jack.domain.com 则是生产环境。问题来了,前端代码是同一份,它需要根据当前 hostname 所属的环境来调用不同环境的接口。
当然这个问题也是 split 一把梭就能解决的,但这并不优雅。回到正则表达式上,我们先分析需求,假设公司一级域名只有 domain.com 的,那么这个问题就是提取 appid (例子中的 jack) 与 .domain.com 中间的部分。
1 | var reg = /\w+\.(\w+\.)?domain.com/; |
如上代码的正则表达式中,关键是 (\w+\.)? 这段,它表示匹配零次或一次,并且小括号是分组,可在 match 的结果中直接捕获到分组里的值。
补充1:分组里拿到的结果是 alpha.,多了个 . 不走心,怎么把它去掉呢?可以改成 ((\w+)\.)? 这样 alpha 就要在第 2 组捕获里拿到了,因为第 1 组仍是 alpha.
补充2:试试 (?:(\w+)\.)? 这里 (?:) 表示不产生分组号,于是仍可在第 1 组捕获中拿到 alpha
补充3:\w 匹配字母数字和下划线,如果你的 hostname 中包含其他字符,比如扩充成 [\w-] 就可以包含中划线 -
补充4:加入公司的一级域名有多个,那也可以对 domain.com 再进行扩充。
1 | var reg = /\w+\.(?:(\w+)\.)?(domain|abc|xyz).com/; |
正则表达式的书写是逐步细化的,还是要先分析好需求,写的不多余。
2、引号替换
在一些老项目里 JavaScript 代码经常存在单引号双引号混用,很不规范,让以后的维护者看着很累。虽然现在我们都会使用 ESLint 来自动修复,还是想举这个例子来作为正则表达式的一个 case
1 | { |
现在希望把这段 JSON 对象改成 key 不带引号,value 都为单引号。观察下这份数据,key 和 value 都有单引号和双引号,于是我的想法是先把所有双引号改成单引号,然后再把 key 的单引号去掉。
双引号 → 单引号,我第一次写出来是这样的:
1 | replace(/"(.*)"/g, '$1') |
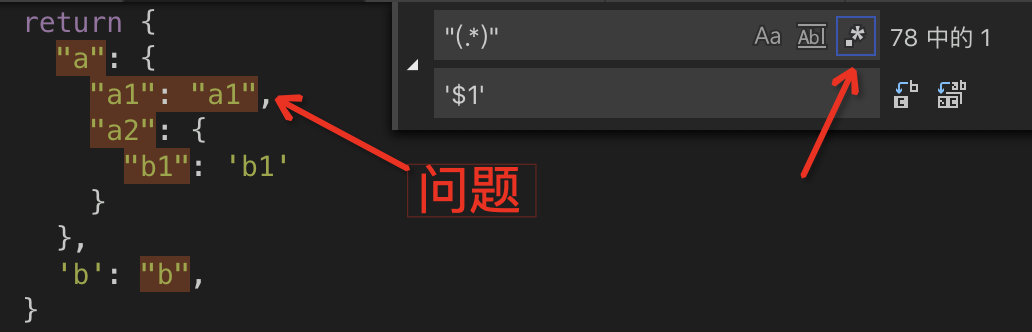
大部分 IDE 的 find-replace 功能都支持写正则,不妨可以试试看,上面这段正则有什么问题。
.* 也匹配了双引号,上面 "a1":"a1" 被 ".*" 匹配了,这是典型的过度匹配。解决办法是使用 [^"]* 或者使用 .*? 以表示尽可能少的重复。这就说到了正则表达式中的贪婪与惰性。
贪婪与惰性
![]()
图片示例来自《JavaScript 正则表达式迷你书》
上面这张图解释了正则引擎的匹配过程,正则表达式是 ".*",待匹配的字符串是 "abc"de
- 第 1 步,初始化,当前状态指向正则中的第1个
",并且开始读取待匹配字符串。 - 第 2 步,发现正则中的第1个
"正好能匹配字符串。 - 第 3 步,当前状态指向正则中的
.*,并且读取字符串的指针也向前移动,巧了,a也被匹配上了。 - 第 4 ~ 8 步,真香真香,
.*一直匹配到字符串末尾了!坑了,我这正则.*后面还有个"要怎么办? - 第 9 步,读取字符串的指针回退一格。这就是正则匹配中的回溯。
- 第 10 步,回退完发现正则最后的
"还是没法匹配e,于是继续回退。 - 第 11 步,回退完还是不能匹配,再回退。
- 第 12 步,现在读取字符串的指针在
"上,不容易,终于匹配上了!
上述过程中,.* 是贪婪的,一开始会把字符串里的 abc"de 都匹配进去,然后正则发现这是条死路,再一步步回退,直到正则能够继续匹配下去。这个过程就是 NFA 中的回溯法。
而当使用了惰性模式后,如将 .* 改成 .*?,它会尽可能少地匹配。不妨试下以下两个例子,观察两个分组里捕获到的内容。
1 | '12345'.match(/(\d{1,3})(\d{2})/) |
回溯的深渊
然而正则中的贪婪和回溯也有个天坑,那就是 ReDos,即正则表达式里的 Deny of Service。可以试试如下代码:
1 | 'aaaaaaaaaaaaaaaaaaaaaaaaaaaab'.match(/^(a+)+$/) |
当正则表达式中出现有歧义的片段时,如 /(a+)+/,字符串里的 a 既可以被 a+ 匹配,又可以被 (a+)+ 匹配,这就容易产生问题。按照上面回溯法的原理,a+ 会先一路把 a 都匹配完,然后发现糟了,正则表达式最后还有个 +,于是一个个字符回退,直到发现 (a+)+ 能匹配时又会一路把 a 都匹配完,然后发现行尾符匹配不了,会再次回溯尝试。随着字符串长度的增加,回溯次数会呈指数级增长,终将导致 Deny of Service。
ReDos 的内容更多在安全领域,笔者只粗略了解下。平时书写正则表达式的时候尤其要留意嵌套的 * 和 +。
3、字符串去重
你可能在算法题里也见过字符串去重,去掉字符串中重复的字符。本文这里不讨论算法,想说明通过正则表达式也能判断用户的输入里有无重复字符。这里需要先学习正则里的几个武器。
反向引用 (back reference)
简单说就是在一个正则表达式中引用一个分组的子表达式。举个 HTML 标签的例子,如果要匹配 <h1></h1> 标签,可以这么写 /<(h[1-6])>[\s\S]*<\/\1>/ 这个正则可以匹配任意合法的 h 标签,其中 \1 就代表第 1 个分组的反向引用,否则就得为 h1 ~ h6 各写一个表达式就很累赘。反向引用的关键在于前面要先有分组,否则 \1 是无效的。
先行断言 (look ahead) / 后行断言 (look behind)
先行断言的语法形式为 /c(?=a)/,表示匹配 a 左边的 c。为了避免与断言中的「前」和 「后」混淆,这里就用「a 左边的 c」来表达。

先行断言有些地方也叫「前瞻断言」或「前向查找」,想象你自己就是一个指针,扫描字符串的过程就像指针在向前移动。
先行断言也有其否定形式,叫做先行否定断言,如 /c(?!a)/,即匹配「非a」左边的 c,其实这与 /c(?=[^a])/ 效果相同,感兴趣的朋友可以自己试试。
所有的正则引擎都支持先行断言和先行否定断言。到了 ES2018 才支持后行断言,细节可参考 ECMAScript 6 入门的正则章节。
尤其需要提一点的是,断言中的文本不会包含在最终的匹配结果里,怎么理解呢?/c(?=a)/ 只会匹配 c,(?=a) 既不会产生分组,也不会出现在 match 函数的结果中,可以试下 'cat'.match(/c(?=a)/)。容易犯的错误是不小心写成了 /c(?=a)t/ 那就 GG 了,这是个永远不可能匹配的正则表达式。
现在我们回到字符串去重的问题上,用上面的武器很容易想到,用先行断言配合反向引用。直观上的理解就是自己作为一个扫描指针,先往前面看,在远处能不能找到和当前脚下相同的字符。
1 | 'abcdaccd'.replace(/(.)(?=.*?\1)/g, '') // bacd |
上面的字符串用正则替换后为什么是 bacd,不应该是 abcd 么?因为 /(.)(?=.*?\1)/ 匹配的是第1个 .,断言并不会出现在匹配结果里,所以理解起来就是扫描指针在当前位置时,先往前面看,如果有看到相同的字符,就把当前脚下的字符替换成空。
如果想让替换后的结果是 abcd 该怎么写正则呢?显然要用后行断言,就是扫描指针在当前位置时,往身后看,如果有看到相同的字符,就把当前脚下的字符替换成空。
1 | 'abcdaccd'.replace(/(.)(?<=\1.*?\1)/g, '') // abcd |
看到这个正则可能又困惑了,后行断言难道不都是 /(?<=y)x/ 这么写的么?这就是黑科技了,因为用到反向引用,就得保证正则表达式中要先出现分组,所以 /(?<=\1.*?\1)(.)/ 这种表达式里的 \1 是无效的。
注:此法来自正则实现数组滤重
4、定制 .vue 单文件模板
最近在做微信小程序,每个页面都必须写 wxml / wxss / js / json 这 4 个文件,当项目里页面多的时候文件就巨多无比。假如没有用任何开发框架,可以自己定制一个单文件模板,有点类似 .vue 文件。
1 | <template> |
现在我们的目标是把这个文件拆成模板、样式、js 和 json 配置对应的 4 个文件,抛弃原来的 split 大法或者逐行读文件,正则表达式可以帮我们优雅地解决问题。
修饰符
在前面的正则表达式中见到了 /.*/g,其中的最后那个 g 就是正则表达式的修饰符。
常用的修饰符有
i:ignore casem:multilineg:global
很好记,合起来 img,ES6 中又新增了几种修饰符,细节可参考 ECMAScript 6 入门的正则章节。
多行模式 (multiline)
上面这个问题需要用到正则表达式中的多行模式,因为要在代码文件中做匹配,肯定涉及到换行。
当使用了 m 修饰符后,多行模式下会更改 ^ 和 $ 的含义,使它们分别在任意一行的行首和行尾匹配,而不是整个字符串的开头和结尾。

回到刚才的问题,如何提取 <template></template> 标签之间的内容,首先会想到 /<template>(.*)<\/template>/m,然而可以试试发现不行。这是因为 . 匹配的是除 \r \n 之外的任何单个字符,并不是所有任意字符。所以正则表达式需要改成 /<template>([\s\S]*)<\/template>/m,分组中捕获的就是标签之间的内容。
同理,匹配 <style> 标签里的样式,可以写出 /<style(?:\s+lang="(\w+)")?>([\s\S]*?)<\/style>/mg 其中 <style(?:\s+lang="(\w+)")?> 可以同时匹配 <style> 与 <style lang="stylus">,并且可以从分组捕获中拿到 lang 属性的值。另外要提的是,.vue 文件里可能会写多个 <style>,所以这个正则表达式中要使用 m 和 g 两个修饰符,并且在标签内容的里要使用 [\s\S]*? 以表示惰性(尽可能少的匹配)。
最后就是区分 <script> 标签了,在我们定制的模板中,存在着 <script type="json"> 这是我们自己约定的写 JSON 配置的地方,而普通的 <script> 或 <script type="text/javascript"> 则是写 JavaScript 代码。用先行否定断言,可以写出 /<script(?!\s+type="json").*?>([\s\S]*?)<\/script>/m 来提取 JavaScript 代码。这里可以体会下,如果前面半段写成 /<script(?!\s+type="json")>/ 的话,就无法匹配到 <script type="text/javascript"> 了。
JavaScript 中的正则
如果读者看到这儿,说明对正则没有失去信心。🌝
JavaScript 中正则相关的函数有 replace / test / match / exec,上文示例代码中也用过一些了。这里强烈推荐下 exec 函数,当使用了 g 修饰符时,如果字符串中有多处匹配,match 函数无法拿到每处匹配中的分组信息,这就需要用 exec 来处理了。
1 | var reg = /¥(\d+)/g; |
RegExp 对象里的 exec 函数可以被多次调用,每次只返回一处匹配的详细信息(包括分组捕获),并且把当前处理到的字符串下标存在 RegExp 的 lastIndex 中,这样就可以在 g 全局模式下得到每处匹配的分组信息。
ES6 后的新增特性
ES6 之后对正则表达式的新增了不少特性,主要在对 Unicode 的支持上。如果你去网上搜那些正则表达式大全,很有可能会搜到用 /[\u4e00-\u9fa5]/ 来识别汉字,这是很久以前的做法。现在的字符集更多了,不妨试试 𠮷 の 或者 😂 呢?先来看个例子:
1 | console.log('😂'.length); // 2 |
可以看到 😂 由 2 个双字节码组成 (UTF-16),可以在 codepoints 上查到它的所有编码格式,显然它已经超出了 /[\u4e00-\u9fa5]/ 的范围。你可能会说,它又不是汉字,当然不能用上面那个正则,那不妨再查下 𠮷 的编码。
ES6 对正则表达式有个 u 修饰符,表示 Unicode 模式。在这个模式下,正则中的 . 可以匹配换行符以外的任意单个字符(包括 Unicode 字符)。
1 | /./.test('😂'); // true 因为 😂 被认为是2个字符,相当于 '\uD83D\uDE02' |
Unicode 模式下还可以用 \u{unicode值} 来表示码点大于 0xFFFF 的 Unicode 字符。
此外,ES2018 还引入了 Unicode 属性转义,比如可以用 /\p{Unified_Ideograph}/u 来匹配所有汉字。其中 Unified_Ideograph 是一个 Unicode property 表示汉字字符集,可在 tc39 中查到所有属性转义。
当然,ES6 和 ES2018 还增加了另外2个修饰符,以及后行断言和具名分组,出于篇幅原因这里就不多介绍了,有兴趣的可以参考 ECMAScript 6 入门的正则章节。
总结
正则表达式是前端工程师的一把利器,也是值得每个程序员掌握的。本文抛砖引玉,主要想说明正则表达式在前端中有着很多应用场景,而不仅仅是纯粹的表单验证。
正则表达式的语法看着多而复杂,但只要从语法的功能分类入手,平时多写多运用,就能很快克服语法的记忆负担。书写正则表达式的过程也体现着思考的过程,正则的细化也就是需求的细化。
最后再次推荐入门书籍《正则表达式必知必会》,以及正则表达式的可视化工具 regulex。
参考资料